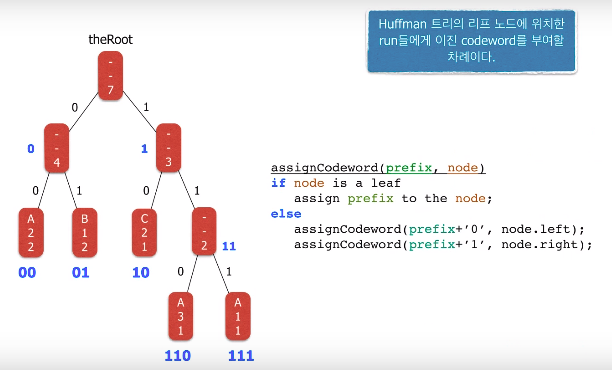
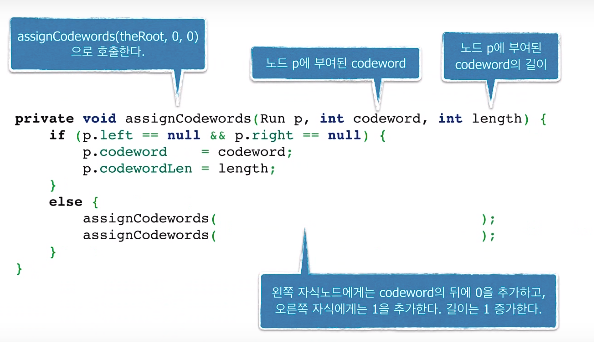
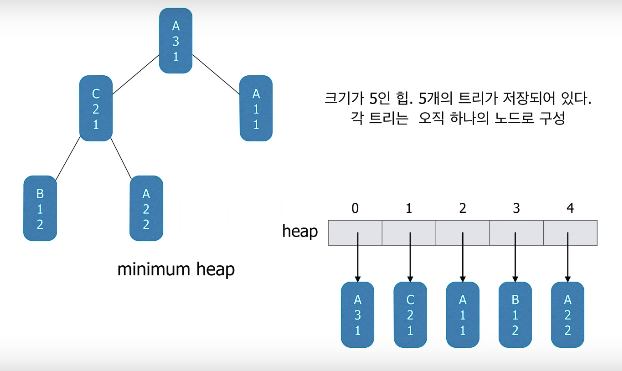
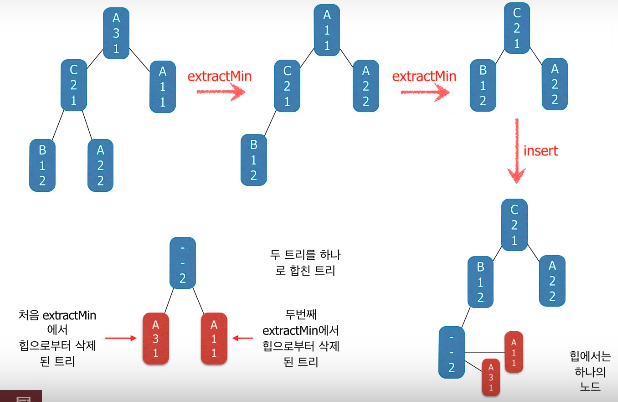
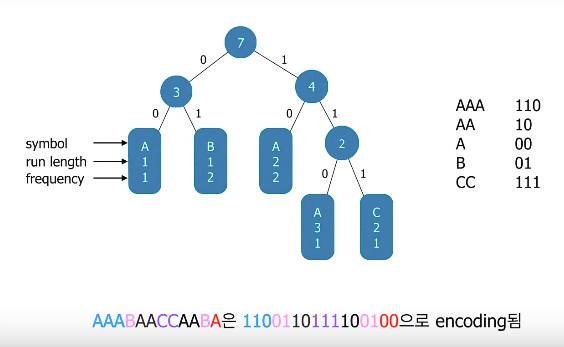
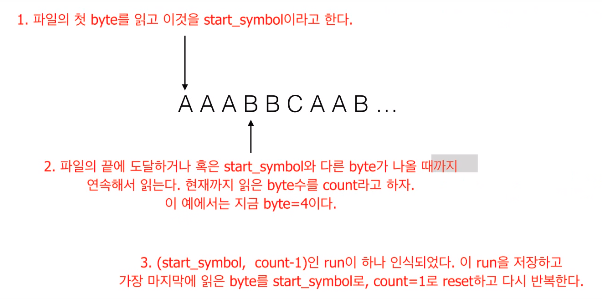
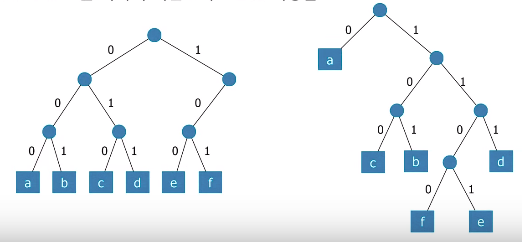
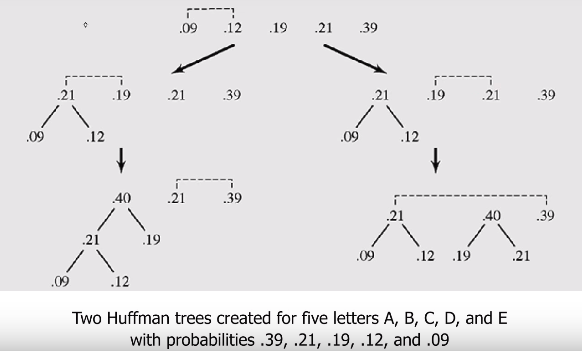
EclEmma
EclEmma는 자바에서 테스트 커버리지를 측정해 주는 이클립스 플러그인 입니다. 설치 방법 및 사용 방법은 아주 간단하지만 한번 보도록 하죠.
EclEmma 설치
-
이클립스 상에서
help -> Eclipse MarketPlace...를 누른 후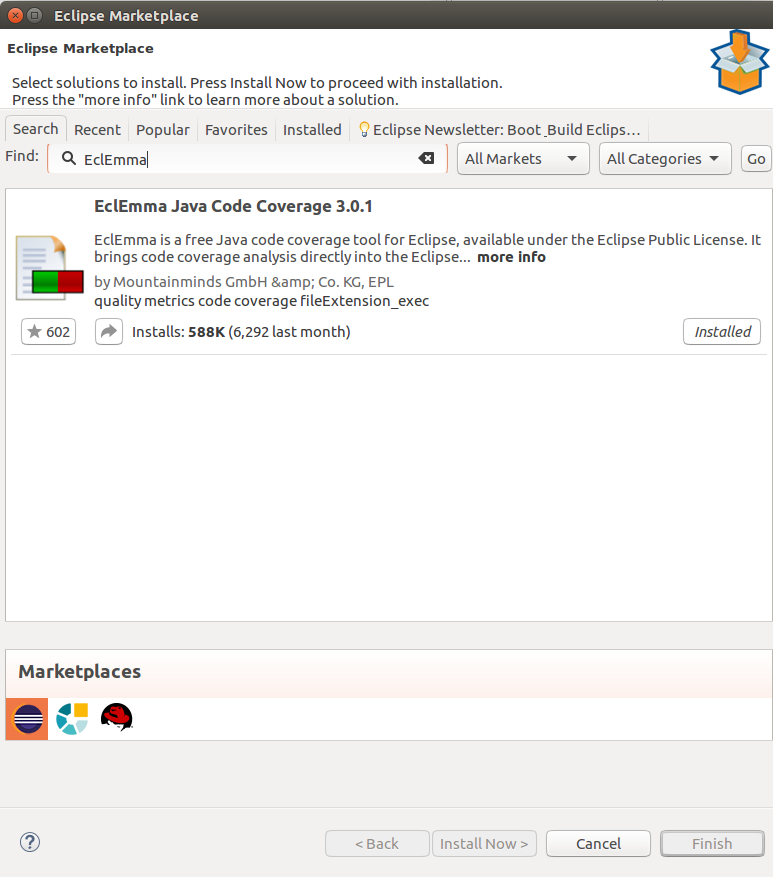
Install버튼을 눌러서 설치 해 줍니다.
실행
-
초/빨 색의 막대바가 있는 실행 버튼이 생깁니다.

-
그러면 아래와 같이 프로젝트, 패키지, 클래스에 대한 결과를 볼 수 있습니다.
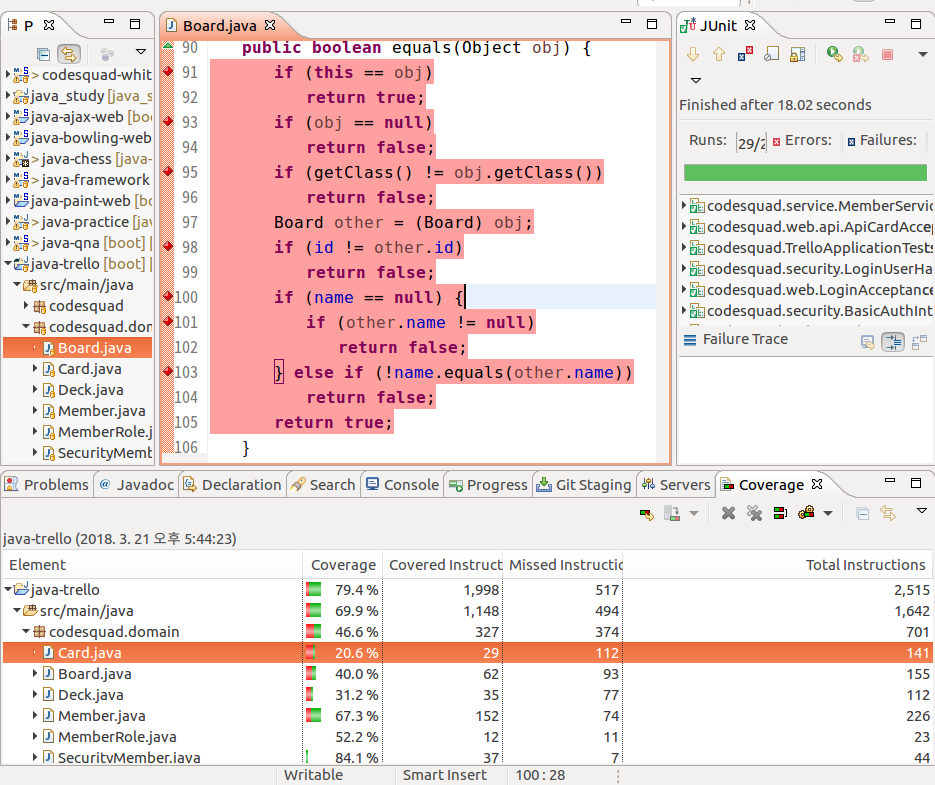
녹색 : 테스트로 검증 된 분분
빨간색 : 테스트가 필요한 부분
노란색 : 부분적으로 테스트 된 곳
여담
사실 도메인 단에서 커버리지가 많이 떨어지길래 모델에 대한 유닛 테스트는 꼼꼼히 작성 했다고 생각했던지라 나름 충격을 받아서 보니 이클립스를 통해 Generate hashcode() and equals()로 만든 메서드 부분이 문제였네요…
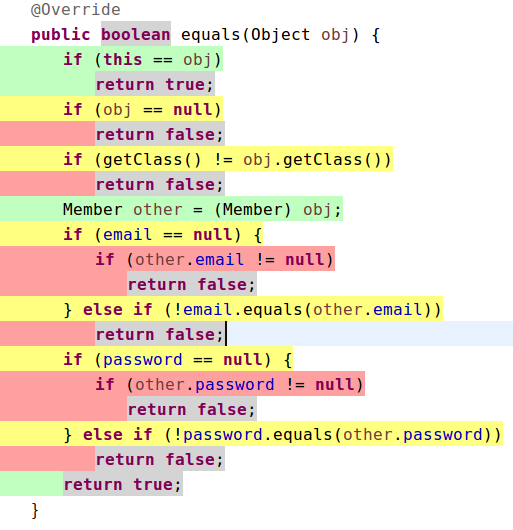
경우에 따라선 똑같이 자동으로 만든 equals() 메서드가 초록, 노랑, 빨간이 알록달록하게 뜨는 경우를 보게 되기도 합니다.
특히 로직이 별로 없는 모델이 있을 경우 커버리지가 확 떨어지는 결과가 나오는 군요. 커버리지를 올리기 위해 테스트 코드를 작성하면 해결 될 일이긴 하지만, 정말 hashcode(), equals()에 대한 테스트 코드까지 매번 만들어 줘야 할지는 단순히 숫자에 대한 강박으로 커버리지를 올리기 위한 작업은 아닌가 싶은 생각이 들어서 한번 생각 해 봐야 할 것 같네요.