
인프런의 영리한 프로그래밍을 위한 알고리즘 강좌를 보고 작성한 문서입니다.
Case Study : Huffman Coding
압축의 종류 :
-
무손실(lossless) : 손실 되면 안되는 정보들을 담는 경우. 텍스트 등등
-
손실(lossy) : 손실 되더라도 사람이 인지 못할 정도면 문제 없는 경우. 동영상…
Huffman Coding
-
가령 6개의 문자 a, b, c, d, e, f로 이루어진 파일이 있다고 하자. 문자의 총 개수는 100,000개이고 각 문자의 등장 횟수는 다음과 같다.

-
고정길이 코드를 사용하면 각각의 문자를 표현하기 위해서 3비트가 필요하며, 따라서 파일의 길이는 300,000비트가 된다.
-
위 테이블의 가변길이 코드를 사용하면 224,000비트가 된다.
Prefix Code
-
어떤 codeword도 다른 codeword의 prefix가 되지 않는 코드(여기서 codeword란 하나의 문자에 부여된 이진코드를 말함)
-
모호함이 없이 decode가 가능함
-
prefix code는 하나의 이진트리로 표현 가능함
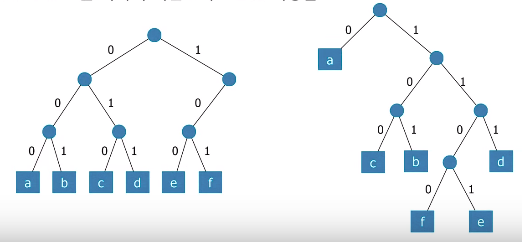
Huffman Coding
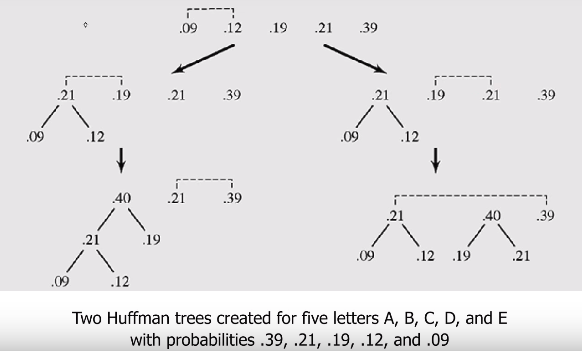
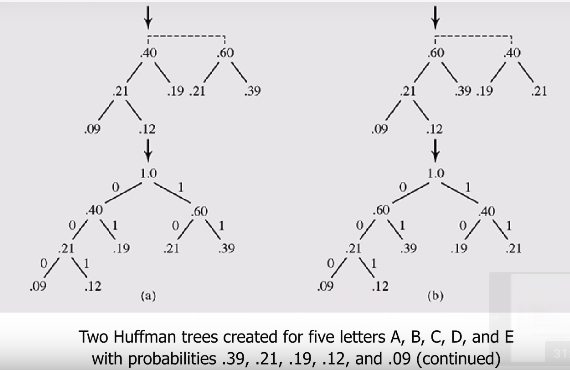
왼쪽과 오른쪽 둘 다 압축률은 같다.

Run-Length Encoding
-
런(run)은 동일한 문자가 하나 혹은 그 이상 연속해서 나오는 것을 의미한다. 예를 들어 스트링 s = “aaabba”는 다음과 같은 3개의 run으로 구성된다: “aaa”, “bb”, “a”.
-
run-length encoding에서는 각각의 run을 그 “run을 구성하는 문자”와 “run의 길이”의 순서쌍 (n, ch)로 encoding한다. 여기서 ch가 문자이고 n은 길이이다. 가령 위의 문자열 s는 다음과 같이 코딩된다: 3a2b1a.
-
Run-length encoding은 길이가 긴 run들이 많은 경우에 효과적이다. 아닌 경우 압축의 효과가 적음, 이미지나 멀티미디어 데이터의 경우 효율적(유사 픽셀이 연속적으로 나옴)
-
무손실 압축이다.