
인프런의 영리한 프로그래밍을 위한 알고리즘 강좌를 보고 작성한 문서입니다.
Huffman Method with Run-Length Encoding
압축의 종류 :
-
파일을 구성하는 각각의 run들을 하나의 super-symbol로 본다. 이 super-symbol들에 대해서 Huffman coding을 적용한다.
-
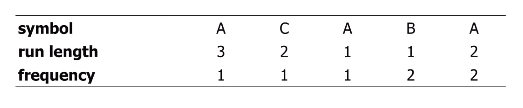
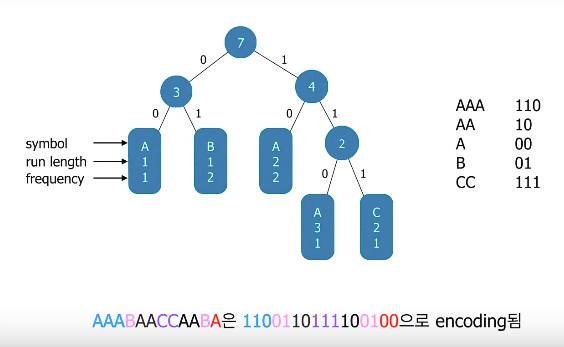
예를 들어 문자열 AAABAACCAABA은 5개의 super-symbol들 AAA, B, AA, CC 그리고 A로 구성되며, 각 super-symbol의 등장횟수는 다음과 같다.
제1단계 : Run과 frequency 찾기
-
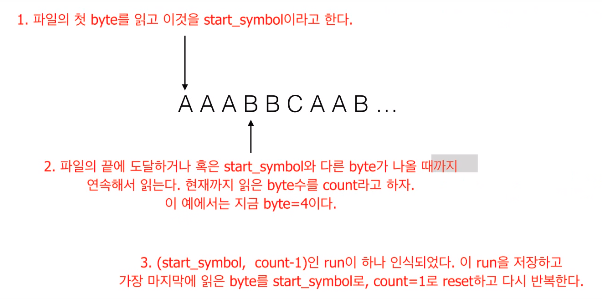
압축할 파일을 처음부터 끝까지 읽어서 파일을 구성하는 run들과 각 run들의 등장횟수를 구한다.
-
먼저 각 run들을 표현할 하나의 클래스 class Run을 정의한다. 클래스 run은 적어도 세 개의 데이터 멤버 symbol, runLen, 그리고 freq를 가져야 한다. 여기서 symbol은 byte타입이고, 나머지는 정수들이다.
-
인식한 run들은 하나의 ArrayList에 저장한다.
-
적절한 생성자와 equals 메서드를 구현한다.
-
데이터 파일을 적어도 두 번 읽어야 한다. 한 번은 run들을 찾기 위해서, 그리고 다음은 실제로 압축을 수행하기 위해서.
-
여기서는 RandomAccessFile을 이용하여 데이터 파일을 읽어본다.
// 읽을 데이터 파일을 연다
RandomAccessFile fIn = new RandomAccessFile(fileName, "r");
// 한 byte를 읽어 온다. 읽어온 byte는 0~255사이의 정수로 반환된다.
// 파일의 끝에 도달하면 -1을 반환한다.
int ch = fIn.read();
// 필요하다면 byte로 casting해서 저장한다.
byte symbol = (byte)ch;
Run 인식하기
Run과 frequency 찾기
JAVA
public class HuffmanCoding {
// 인식한 run들을 저장할 ArrayList를 만든다.
private ArrayList<Run> runs = new ArrayList<Run>();
private void collectRuns(RandomAccessFile fIn) throws IOException {
// 데이터 파일 fIn에 등장하는 모든 run들과 각각의 등장횟수를 count하여
// ArrayList runs에 저장한다.
}
static public void main(String args[]){
HuffmanCoding app = new HuffmanCoding();
RandomAccessFile fIn;
try {
fIn = new RandomAccessFile("sample.txt","r");
app.collectRuns(fIn);
fIn.close();
} catch (IOException io) {
System.err.println("Cannot open " + fileName);
}
}
}
C
typedef struct run Run;
typedef struct run {
unsigned char symbol;
int run_length;
int freq;
};
Run *runs[MAX];
int number_runs = 0;
void collectRuns(FILE *fIn){
// 데이터 파일 fIn에 등장하는 모든 run들과 각각의 등장횟수를 count하여
// 배열 runs에 저장한다.
// Run 객체들을 동적메모리할당으로 생성하여 배열 runs에서 객체의 주소를 저장하고
// 배열의 크기가 부족할 경우 array doubling을 하도록 구현하라.
}