인프런의 영리한 프로그래밍을 위한 알고리즘 강좌를 보고 작성한 문서입니다.
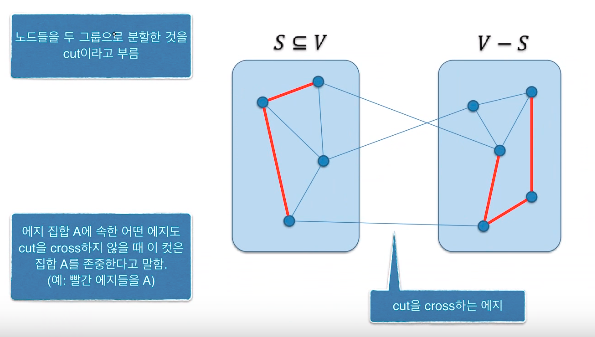
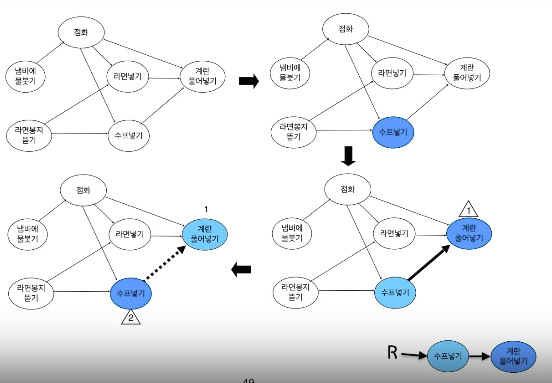
서로소인 집합들의 표현
-
각 집합을 하나의 트리로 표현
-
예 : 2개의 집합
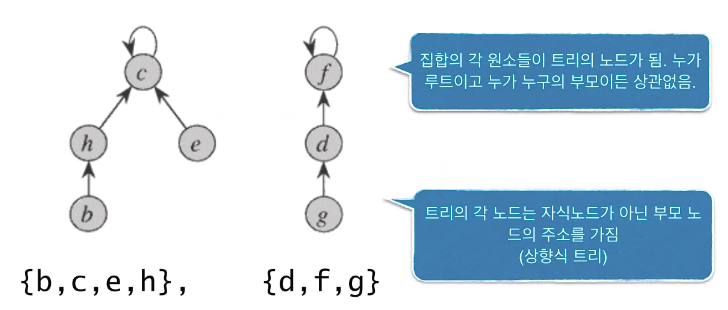
-
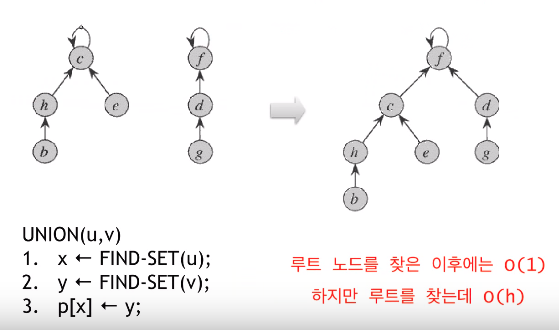
누가 부모인지는 중요하지 않다.
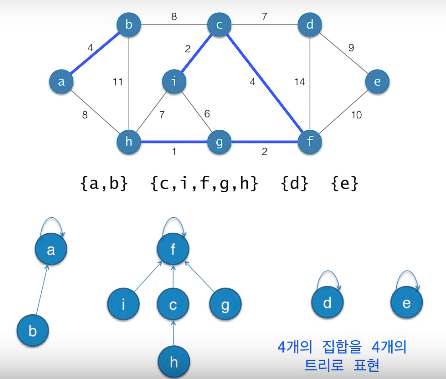
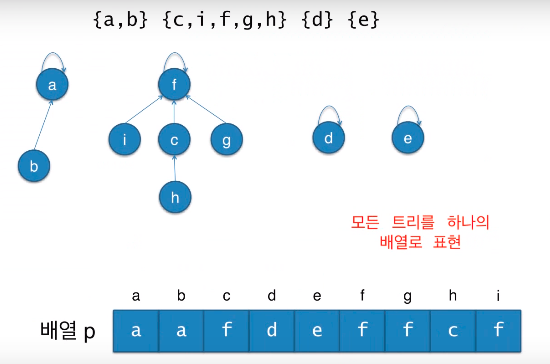
Find-Set(v)
-
자신이 속한 트리의 루트를 찾음

Union(u, v)
-
한 트리의 루트를 다른 트리의 루트의 자식 노드로 만듬
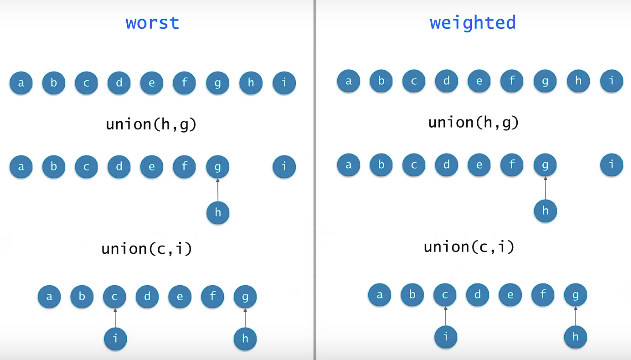
Weighted Union
-
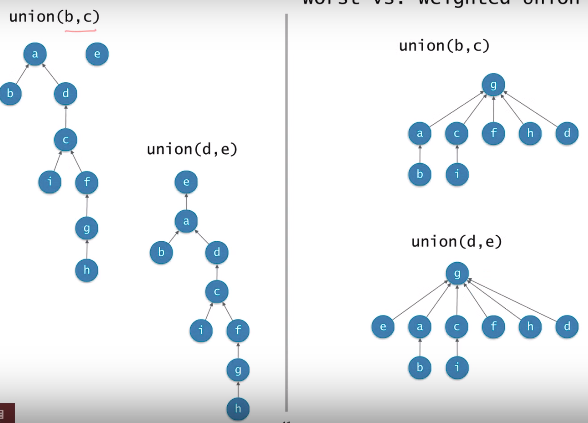
두 집합을 union할 때 작은 트리의 루트를 큰 트리의 루트의 자식으로 만듬 (여기서 크기란 노드의 개수)
-
각 트리의 크기(노드의 개수)를 카운트하고 있어야

Worst vs Weighted Union


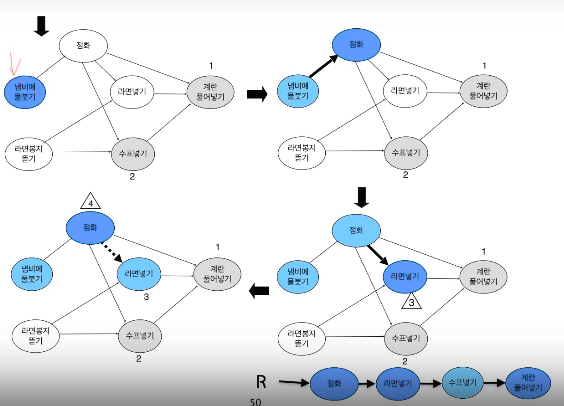
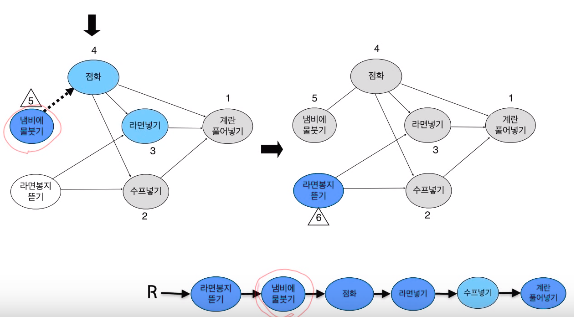
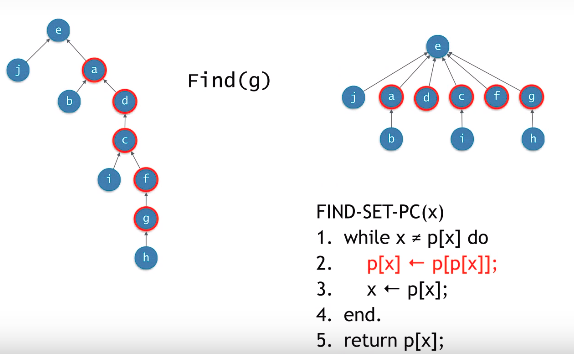
Path Compression
-
다 루트의 자식들로 만들어 간다.
-
find를 하면서 찾기만 하지 않고 루트의 자식으로 만들어 버려서 높이를 낮춘다.
-
간단하게는 처음 루트를 찾고 다시 한번 반복하여 루트에다가 옮긴다.
-
FIND-SET-PC(x)에 빨간 코드를 이용하면 루트에 옮기는게 아니라 자신의 부모의 부모에다 옮기는 형식으로 한다.(Find한 경로를 절반의 높이로 만든다.)
Weighted Union with Path Compression (WUPC)

log*(로그 스타) 함수란?
-
(log log log … log N) 이렇게 로그를 여러번 했을때 1이 되는 횟수
-
5보다 클 일이 없는 수(현실에서는 거의 불가능)
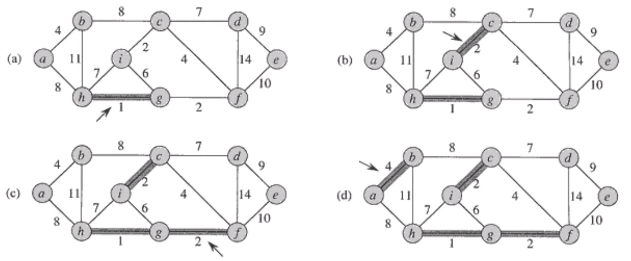
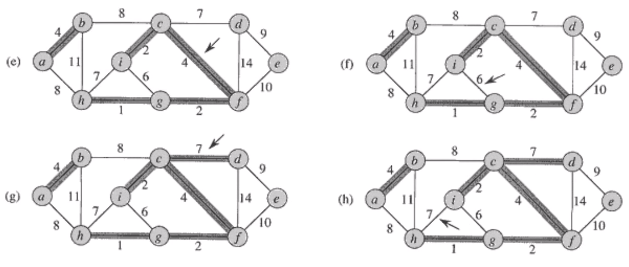
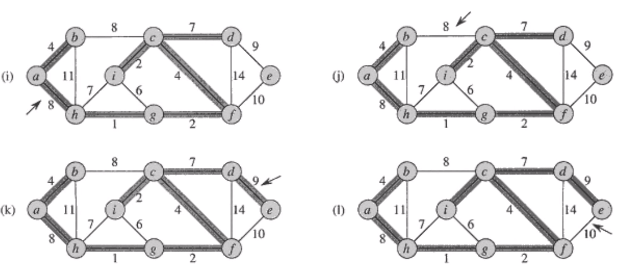
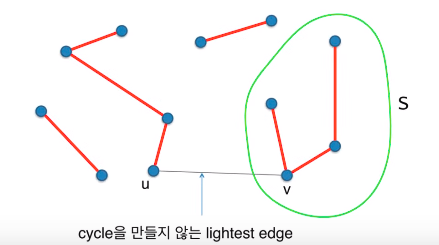
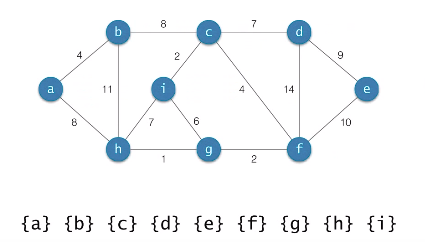
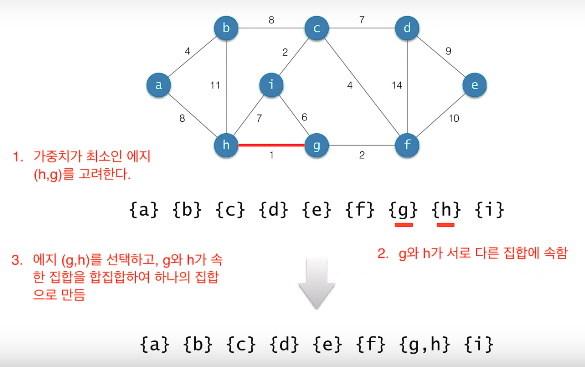
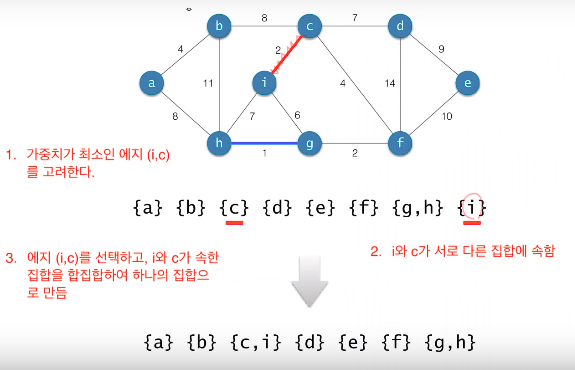
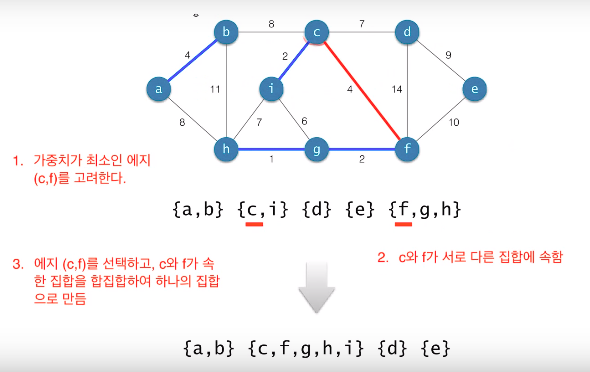
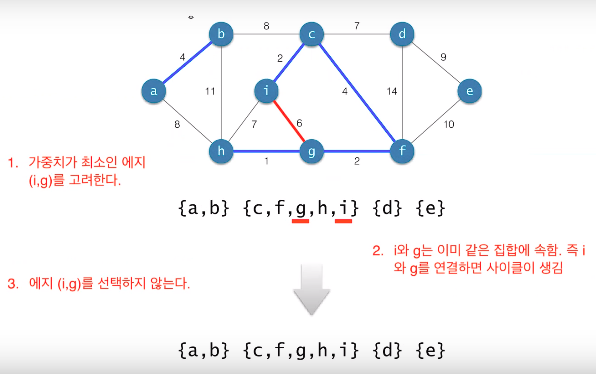
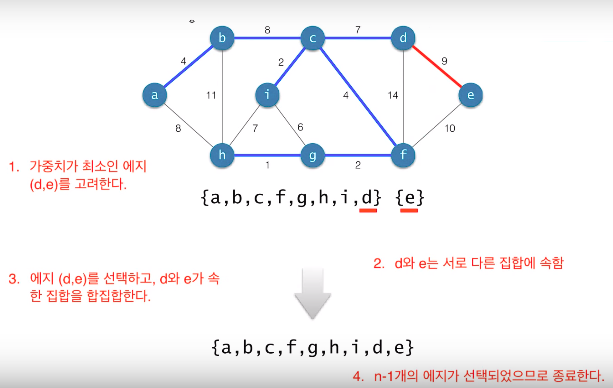
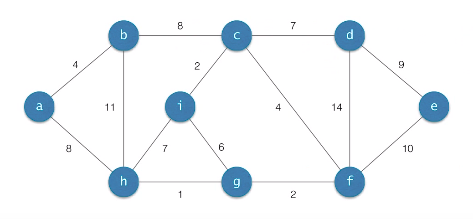
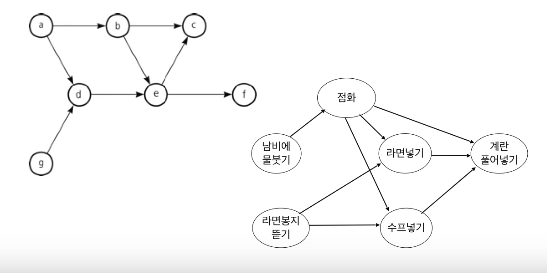
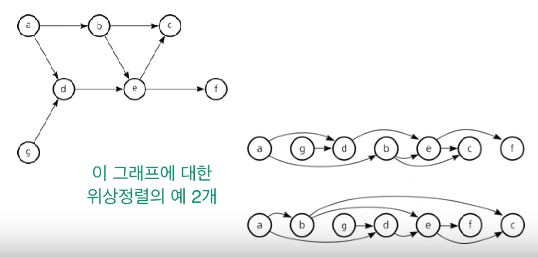
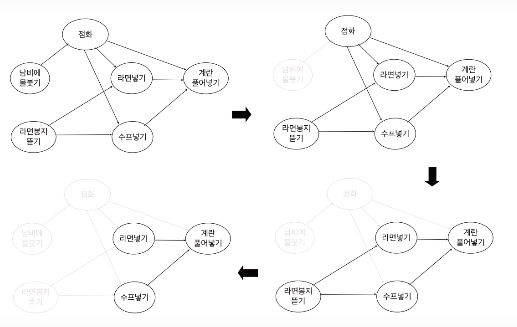
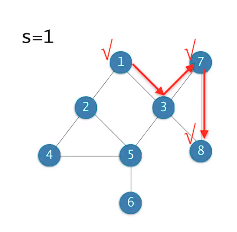
Kruskal의 알고리즘
-
시간복잡도