브라우저의 구조
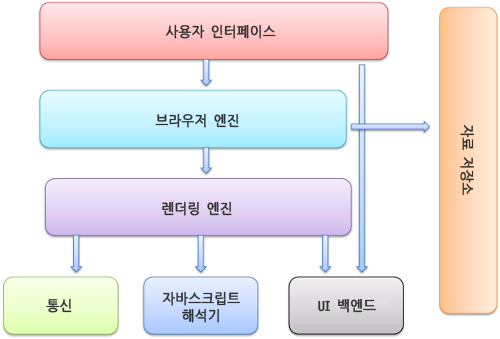
시작하기에 앞서 브라우저의 구조를 보도록 하겠습니다.
-
사용자 인터페이스 : 주소 표시줄, 이전/다음 버튼, 북마크 메뉴 등. 요청한 페이지를 보여주는 창을 제외한 나머지 모든 부분
-
브라우저 엔진 : 사용자 인터페이스와 렌더링 엔진 사이의 동작을 제어
-
자료 저장소 : 자료를 저장하는 계층. 쿠키를 저장하는 것과 같이 모든 종류의 자원을 하드 디스크에 저장할 필요가 있다. HTML5 명세에는 브라우저가 지원하는 ‘웹 데이터 베이스’가 정의되어 있다.
-
렌더링 엔진 : 요청한 콘텐츠를 표시. 예를 들어 HTML을 요청하면 HTML과 CSS를 파싱 하여 화면에 표시
-
통신 : HTTP 요청과 같은 네트워크 호출에 사용됨. 이것은 플랫폼 독립적인 인터페이스이고 각 플랫폼 하부에서 실행
-
자바스크립트 해석기 : 자바스크립트 코드를 해석하고 실행
-
UI 백엔드 : 콤보 박스와 창 같은 기본적인 장치를 그림. 플랫폼에서 명시하지 않은 일반적인 인터페이스로서, OS 사용자 인터페이스 체계를 사용
웹 개발자 입장에서는 웹 페이지의 성능을 고려할 때 주로 신경 써야 하는 부분은 렌더링 엔진이기에 렌더링 엔진에 집중해서 소개 하겠습니다. (다른 곳 자료들이 대부분 렌더링 엔진이라서 그런 건 아니고….)
렌더링 엔진
- 익스플로러 : Trident
- 파이어폭스 : Gecko
- 크롬 : Webkit(27버전 이하), Blink(28버전 이상)
- 사파리 : Webkit
- 오페라 : Presto(14버전 이하), Blink(15버전 이상)
- 엣지 : EdgeHTML, Blink(18년 12월에 Blink로 변경 발표, 관련기사)
렌더링 엔진에는 여러 종류가 있지만 오픈소스이기도 하고 많이 쓰이고 있어 자료가 많은 웹킷(Webkit)를 기준으로 설명을 진행하도록 하겠습니다.
(여담으로 MS의 엣지도 최근에 렌더링 엔진을 엣지HTML에서 블링크로 변경하게 되어 다양성에 대한 우려가 발생하고 있습니다…)
렌더링 과정

앞으로 많이 보게 될 그림으로 렌더링 엔진으 렌더링을 하는 과정입니다.
-
HTML 파싱 : HTML 문서를 읽어 DOM 트리를 구축하는 단계입니다. 평소 하는 DOM 조작이 여기서 만들어진 DOM을 조작하는 것이죠.(말 그대로 DOM을 조작하는 것이지 HTML 문서를 조작하는게 아닙니다.)
-
렌더 트리 구축 : HTML 파싱을 통해 만들어진 DOM 트리와 이후 설명할 CSSOM(DOM 트리와 같은 CSS 판 DOM 트리)를 통해 DOM 트리에 생긴 노드들에 대한 스타일을 매핑 시킨 트리입니다.
-
렌더 트리 배치 : 렌더 트리 내에는 노드에 대한 정보와 스타일에 대한 정보만 가지고 있을 뿐 화면 어느 곳에 위치할지에 대한 정보는 없는데 위치 정보를 계산하는 단계입니다.
-
렌더 트리 그리기 : 계산된 위치 정보를 가지고 실제 사용자 브라우저에 화면을 출력해주는 단계입니다.
자세한 설명은 각각의 단계 때 진행하도록 하겠습니다.
Webkit의 렌더링 과정
설명에 들어가기 앞서 렌더링 엔진의 하나인 웹킷 기반으로 설명을 할 것이라 웹킷의 렌더링 과정을 보도록 하겠습니다.
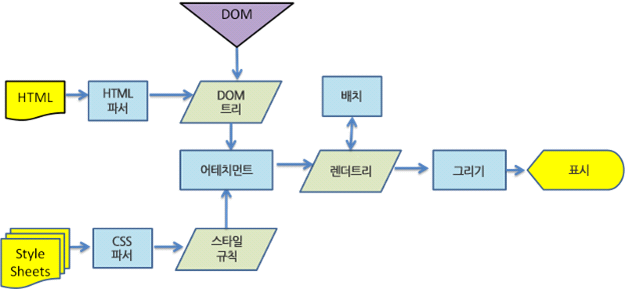
뭔가 많이 복잡해 보이지만
DOM 트리를 구축하는 부분이 좀 더 세분화되었고 HTML만이 아니라 스타일 시트에 대한 작업이 추가되었다는 점만 다르지 기본적인 렌더링 엔진이랑 유사하다는 걸 알 수 있습니다.
이제 첫 단계인 HTML을 파싱 하여 DOM 트리를 생성하는 부분을 보도록 하겠습니다.
DOM 트리 구축 위한 HTML 파싱
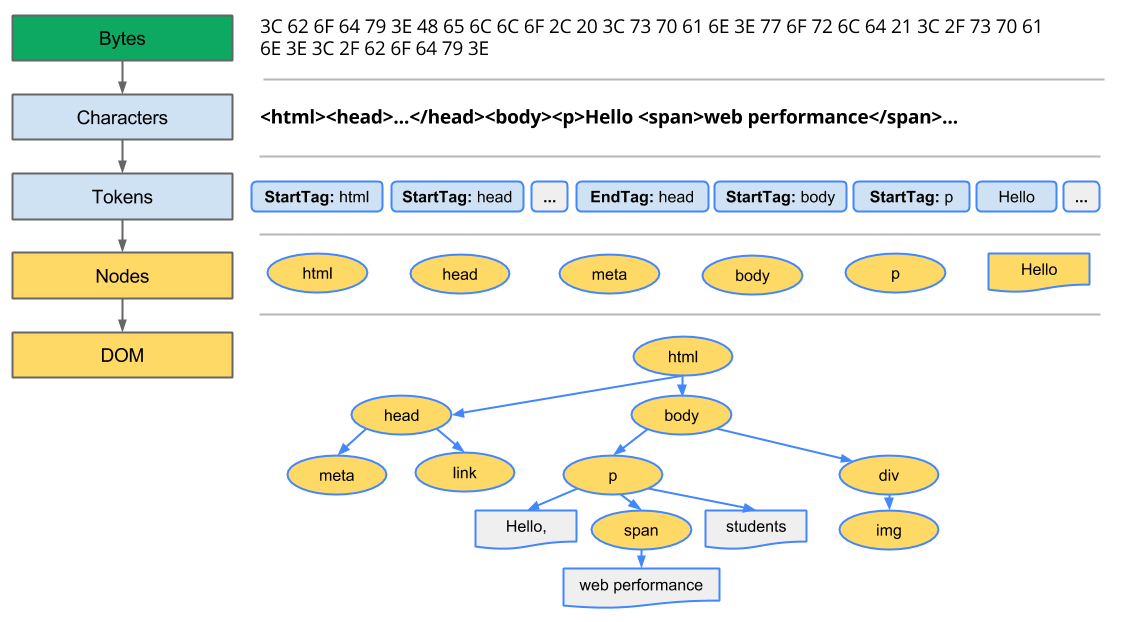
HTML을 파싱 하여 DOM 트리를 생성하는 과정은
-
변환: 브라우저가 HTML의 원시 바이트를 디스크나 네트워크에서 읽어와서, 해당 파일에 대해 지정된 인코딩(예: UTF-8)에 따라 개별 문자로 변환합니다.
-
토큰화: 브라우저가 문자열을 W3C HTML5 표준에 지정된 고유 토큰으로 변환합니다(예: ‘<html>’, ‘<body>’ 및 꺽쇠괄호로 묶인 기타 문자열). 각 토큰은 특별한 의미와 고유한 규칙을 가집니다.
-
렉싱: 방출된 토큰은 해당 속성 및 규칙을 정의하는 ‘객체’로 변환됩니다.
-
DOM 생성: 마지막으로, HTML 마크업이 여러 태그(일부 태그는 다른 태그 안에 포함되어 있음) 간의 관계를 정의하기 때문에 생성된 객체는 트리 데이터 구조 내에 연결됩니다. 이 트리 데이터 구조에는 원래 마크업에 정의된 상위-하위 관계도 포합됩니다. 즉, HTML 객체는 body 객체의 상위이고, body는 paragraph 객체의 상위인 식입니다.
이와 같은 과정을 거칩니다만, HTML 문서를 읽어 가장 밑에 있는 DOM 트리가 생성된다는 점만 확실히 기억하시는 것이 가장 중요합니다.
좀 더 익숙한 형태로 HTML 문서가 어떻게 DOM 트리가 되는지 보죠.
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<link href="style.css" rel="stylesheet">
<title>Critical Path</title>
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg"></div>
</body>
</html>
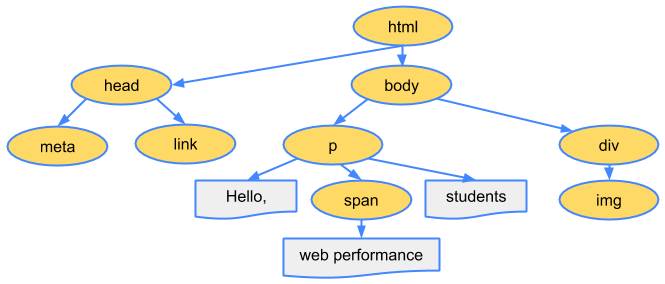
HTML의 모든 요소가 DOM 트리에 포함된 것을 볼 수 있습니다.
이 전체 프로세스의 최종 출력이 바로 DOM(Document Object Model)이며, 브라우저는 이후 모든 페이지 처리에 이 DOM을 사용합니다.
자바스크립트를 통해 조작하는 것도 어디까지나 DOM 이지 HTML이 아니라는 점입니다. 평소 사용하는 말도 DOM 조작이라고 하지 HTML 조작이라고 하지 않는 이유가 여기 있는 것이지요.

(크롬 브라우저 개발자 도구의 performance에서 해당 과정을 확인할 수 있습니다. 좀 더 알아보기)
여기까지가 HTML 문서를 파싱 하여 DOM 트리를 만드는 과정이었습니다.
다만, DOM 트리는 문서 마크업의 속성 및 관계를 포함하지만 요소가 렌더링 될 때 어떻게 표시될지에 대해서는 알려주지 않습니다. 이것은 CSSOM의 책임입니다. CSSOM은 조금 있다가 설명드리도록 하겠습니다.
브라우저의 오류 처리
인터넷을 하면서 HTML 페이지에서 “유효하지 않은 구문”이라는 오류를 본 적이 없을 겁니다. 이는 브라우저가 모든 오류 구문을 교정하기 때문입니다. 아래 오류가 포함된 HTML 예제를 보죠.
<html>
<mytag></mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
HTML에는 존재하지 않는 mytag라던지 잘못 중첩된 p, div태그가 존재해도 파서가 HTML 제작자의 실수를 수정해줍니다.
테이블이 잘 못 된 경우를 보도록 하겠습니다.
<table>
<table>
<tr>
<td>inner table</td>
</tr>
</table>
<tr>
<td>outer table</td>
</tr>
</table>
브라우저는 HTML 문서를 파싱 하다가 테이블 안에 테이블이 있으면
<table>
<tr>
<td>outer table</td>
</tr>
</table>
<table>
<tr>
<td>inner table</td>
</tr>
</table>
자동적으로 HTML 문법에 맞게 테이블을 수정해줍니다.
이에 대해서는 HTML 명세에 따로 존재하지 않아도 다른 브라우저들이 그러했듯이 관습적으로 오류를 고쳐주고 있습니다.
HTML5 명세는 이런 요구 사항 일부를 정의했습니다. 웹킷은 이것을 HTML 파서 클래스의 시작 부분에 주석으로 잘 요약해 두었답니다.
파서는 토큰화된 입력 값을 파싱 하여 문서를 만들고 문서 트리를 생성한다. 규칙에 맞게 잘 작성된 문서라면 파싱이 수월하겠지만 불행하게도 형식에 맞지 않게 작성된 많은 HTML 문서를 다뤄야 하기 때문에 파서는 오류에 대한 아량이 있어야 한다.
파서는 적어도 다음과 같은 오류를 처리해야 한다.
- 어떤 태그의 안쪽에 추가하려는 태그가 금지된 것일 때 일단 허용된 태그를 먼저 닫고 금지된 태그는 외부에 추가한다.
- 파서가 직접 요소를 추가해서는 안 된다. 문서 제작자에 의해 뒤늦게 요소가 추가될 수 있고 생략 가능한 경우도 있다. HTML, HEAD, BODY, TBODY, TR, TD, LI 태그가 이런 경우에 해당한다.
- 인라인 요소 안쪽에 블록 요소가 있는 경우 부모 블록 요소를 만날 때까지 모든 인라인 태그를 닫는다.
- 이런 방법이 도움이 되지 않으면 태그를 추가하거나 무시할 수 있는 상태가 될 때까지 요소를 닫는다.
잠시 웹킷과 게코의 렌더링 엔진을 비교해 보도록 하겠습니다.
Webkit
Gecko
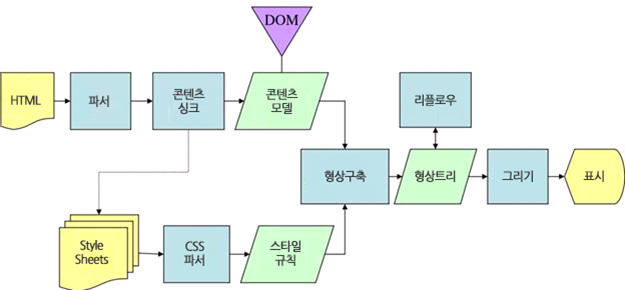
웹킷과 게코의 렌더링 엔진의 동작 과정인데 특정 용어들이 조금 다르지만 기본적으로 동일한 구조를 가진다는 걸 알 수 있습니다.
게코에는 콘텐츠 싱크라는 과정이 추가적으로 존재하지만 웹킷과 비교하여 의미 있는 차이점이라고 보지는 않습니다.
지금까지는 웹킷 기준으로 DOM 트리를 생성하는 부분까지 설명을 하였는데 이제는 어테치먼트가 일어나기 전 스타일 시트에서 CSSOM을 만든 과정을 보도록 하겠습니다.
CSSOM(CSS Object Model)
브라우저가 DOM을 생성하는 동안 CSS 스타일 시트를 만나면 DOM 트리를 만드는 것처럼 스타일 파일을 파싱 하여 CSSOM이라는 트리 구조로 정보를 가집니다.
트리 구조를 가지는 이유에 대해서는 cascade 때문이라는 언급들이 많은데, 부모의 스타일을 자식들한테 상속 시키기 쉽다는 이점을 가집니다. (예: body 요소의 하위인 경우 모든 body 스타일 적용)
body { font-size: 16px }
p { font-weight: bold }
span { color: red }
p span { display: none }
img { float: right }

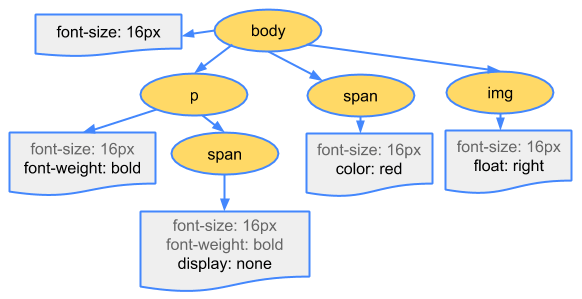
또한, 위의 트리는 완전한 CSSOM 트리가 아니고 스타일 시트에서 재정의하도록 결정한 스타일만 표시합니다. 모든 브라우저는 ‘사용자 에이전트 스타일’이라고 하는 기본 스타일 집합, 즉 개발자가 고유한 스타일을 제공하지 않을 경우 표시되는 스타일을 제공합니다. 개발자가 작성하는 스타일은 이러한 기본 스타일을 간단하게 재정의합니다.
스타일 적용 순서
-
브라우저 선언 (browser declarations)
-
사용자 일반 선언 (user normal declarations)
-
저작자 일반 선언 (author normal declarations)
-
저작자 중요 선언 (author important declarations)
-
사용자 중요 선언 (user important declarations)
밑(5번)으로 갈수록 우선순위가 높습니다.

DOM 파싱과 달리, 타임라인에 ‘Parse CSS’ 항목이 별도로 표시되지 않으며, 대신 파싱 및 CSSOM 트리 생성과 계산된 스타일의 재귀적 계산이 ‘Recalculate Style’ 이벤트에서 캡처됩니다.
렌더 트리
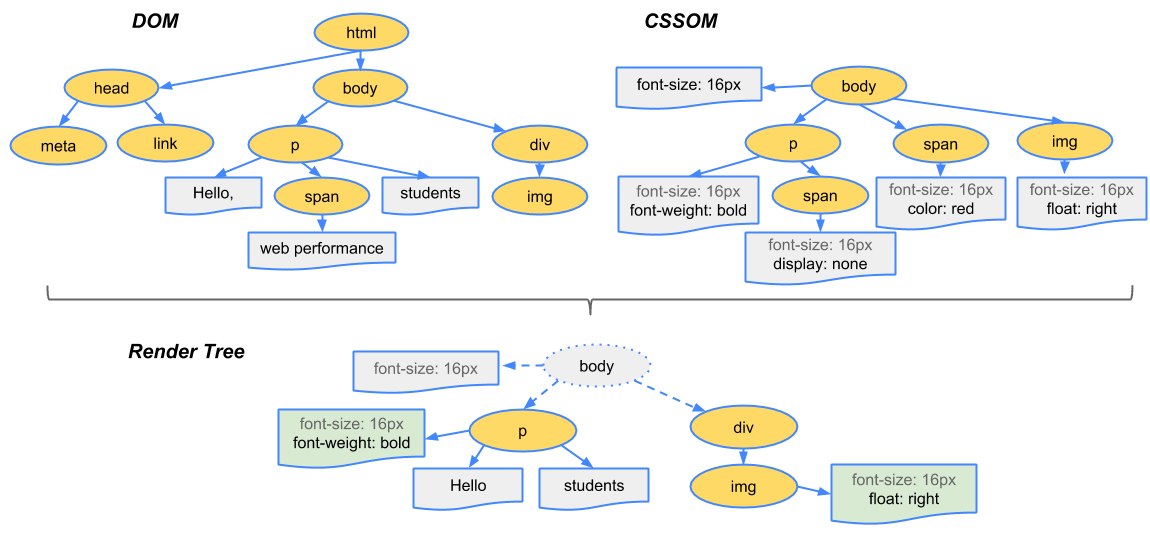
브라우저가 위에서 만든 DOM 트리와 CCSOM을 렌더 트리에 결합합니다. 이 트리는 페이지에 표시되는 모든 DOM 콘텐츠와 각 노드에 대한 모든 CSSOM 스타일 정보를 가지고 있습니다.
렌더 트리를 생성하려면 브라우저가 대략적으로 다음 작업을 수행합니다.
- DOM 트리의 루트에서 시작하여 표시되는 노드 각각을 순회합니다.
-
일부 노드는 표시되지 않으며(예: 스크립트 태그, 메타 태그 등), 렌더링 된 출력에 반영되지 않으므로 생략됩니다.
-
일부 노드는 CSS를 통해 숨겨지며 렌더링 트리에서도 생략됩니다. 예를 들어, 위의 예시에서 span 노드의 경우 ‘display: none’ 속성을 설정하는 명시적 규칙이 있기 때문에 렌더링 트리에서 누락됩니다.
-
표시된 각 노드에 대해 적절하게 일치하는 CSSOM 규칙을 찾아 적용합니다.
- 표시된 노드를 콘텐츠 및 계산된 스타일과 함께 내보냅니다.
1번의 세부사항에서와 같이 화면에 보일 요소에 대해서만 렌더 트리 내의 요소로 포함하기 때문에 CSSOM의 ‘display: none’요소와 DOM 트리 내의 ‘meta’, ‘link’ 태그와 같은 요소는 포함이 되지 않습니다.
다만, visibility: hidden은 display: none과 다릅니다. 전자는 요소를 보이지 않게 만들지만, 이 요소는 여전히 레이아웃에서 공간을 차지합니다(즉, 비어 있는 박스로 렌더링 됨). 반면, 후자(display: none)는 요소가 보이지 않으며 레이아웃에 포함되지도 않도록 렌더 트리에서 요소를 완전히 제거합니다.
즉, 렌더 트리는 화면에 표시되는 모든 노드의 콘텐츠 및 스타일 정보를 모두 포함하는 트리입니다. 렌더 트리가 생성되었으므로 ‘배치(layout)’ 단계로 진행할 수 있습니다.
배치(layout) & 그리기(paint)
지금까지 표시할 노드와 해당 노드의 계산된 스타일을 계산했습니다. 하지만 기기의 뷰포트 내에서 이러한 노드의 정확한 위치와 크기를 계산하지는 않았습니다. 이것이 웹킷에서는 ‘레이아웃’ 단계이며, 게코에서는 ‘리플로우’라고 합니다. 일반적으로 전체 문서에 대해 수행되며 계산 비용은 DOM 크기에 비례합니다.
(뷰포트(view port) 추가 설명 : mozilla, 뷰포트 사용법, 뷰포트란)
페이지에서 각 객체의 정확한 크기와 위치를 파악하기 위해 브라우저는 렌더 트리의 루트(<html> 노드에 해당하는 최상위 렌더러)에서 시작하여 렌더 트리를 순회하면서 각 렌더러에 필요한 크기와 위치 정보를 계산합니다.
최상위 렌더러의 위치는 0,0이고 브라우저 창의 보이는 영역에 해당하는 뷰포트만큼의 면적을 갖습니다.
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<title>Critial Path: Hello world!</title>
</head>
<body>
<div style="width: 50%">
<div style="width: 50%">Hello world!</div>
</div>
</body>
</html>
체험해 보기
위 페이지의 본문에는 두 가지 중첩된 div가 포함되어 있습니다. 첫 번째(상위) div는 노드의 표시 크기를 뷰포트 너비의 50%로 설정하며, 상위 div에 포함된 두 번째 div는 해당 너비를 상위 항목 너비의 50%(즉, 뷰포트 너비의 25%)로 설정합니다.

체험해 보기를 통해 샘플 사이트를 들어가 보면 실제 설명과 같이 적용된걸 볼 수 있습니다.
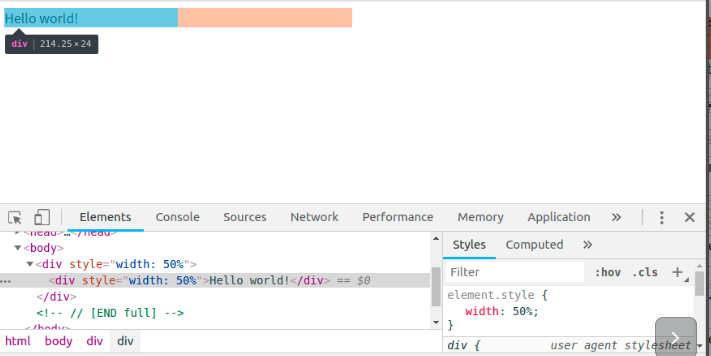
레이아웃 프로세스에서는 뷰포트 내에서 각 요소의 정확한 위치와 크기를 정확하게 캡처하는 ‘박스 모델‘이 출력됩니다. 모든 상대적인 측정값은 화면에서 절대적인 픽셀로 변환됩니다.
마지막으로, 이제 표시되는 노드와 해당 노드의 계산된 스타일 및 기하학적 형태에 대해 파악했으므로, 렌더링 트리의 각 노드를 화면의 실제 픽셀로 변환하는 마지막 단계로 이러한 정보를 전달할 수 있습니다. 이 단계를 흔히 ‘페인팅’ 또는 ‘래스터화’라고 합니다.
이 경우 브라우저가 처리해야 할 작업이 상당히 많으므로 시간이 약간 걸릴 수 있습니다. 그러나 Chrome DevTools는 위에 설명된 세 단계 모두에 대해 몇 가지 정보를 제공할 수 있습니다. 원래 ‘hello world’ 예시의 레이아웃 단계를 검토해 보도록 하겠습니다.

‘Layout’ 이벤트는 타임라인에서 렌더 트리 생성, 위치 및 크기 계산을 캡처합니다.
레이아웃이 완료될 때 브라우저가 ‘Paint Setup’ 및 ‘Paint’ 이벤트를 발생시킵니다. 이러한 작업은 렌더링 트리를 화면의 픽셀로 변환합니다.
렌더링 트리 생성, 레이아웃 및 페인트 작업을 수행하는 데 필요한 시간은 문서의 크기, 적용된 스타일 및 실행 중인 기기에 따라 달라집니다. 즉, 문서가 클수록 브라우저가 수행해야 하는 작업도 더 많아지며, 스타일이 복잡할수록 페인팅에 걸리는 시간도 늘어납니다. 예를 들어, 단색은 페인트 하는 데 시간과 작업이 적게 필요한 반면, 그림자 효과는 계산하고 렌더링 하는 데 시간과 작업이 더 필요합니다.
정리하기
처음에는 복잡해 보였던 렌더링 과정을 다시 보고 정리해 보도록 하죠.
-
HTML 마크업을 처리하고 DOM 트리를 빌드
-
CSS 마크업을 처리하고 CSSOM 트리를 빌드
-
DOM 및 CSSOM을 결합하여 렌더링 트리를 형성
-
렌더링 트리에서 레이아웃을 실행하여 각 노드의 기하학적 형태를 계산
-
개별 노드를 화면에 페인트
HTML, CSS를 보고 각각의 데이터에 대한 트리를 만든 다음, 사용자한테 보여줄 정보를 포함하는 렌더 트리를 만듭니다. 만들어진 렌더 트리를 통해 화면에 어디 보여 줄지 결정하고 그 정보를 가지고 실제 화면에 보여주면 우리들이 매일 만나는 화면이 나타나는 것이죠.
브라우저의 기본적인 동작에 대해서는 배웠는데 HTML, CSS, JS가 어떻게 상호 작용하며 성능에 영향을 끼치는지는 다음에 소개 드리도록 하겠습니다.
참조
developers(구글), 브라우저는 어떻게 동작하는가?(D2)